Clustering Algorithms
K-Means Clustering
The Algorithm
Unlike hierarchical clustering, K-Means clustering involves the user to first specify the number of clusters that the will be created. Initially, the centroids are placed at random points throughout the data set and every item in the data set is assigned to a centroid. The centroids are then moved to the average location of all the data points that are assigned to it. After the data points are reassigned to the centroids, this process repeats until the changes in the reassignments stops. Figure 1 below illustrates this algorithm: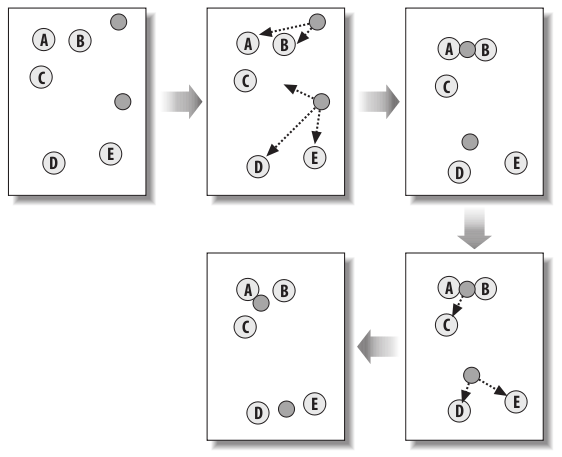
Figure 1. K-Means clustering of five data points. The centroid are represented as dark circles while the data points are represented by letters.
Python Implementation
# K-means clustering - take data rows as input & # of clusters
# Algorithm:
# 1. Place k random centroids & assign to every item
# 2. Move centroids to the avg location of all assigned nodes; reassign objects
# 3. Repeat until objects stop getting assigned
import random
def k_means(rows, distance_metric=pearson_correlation, k=4):
# get the min & max for each pt
ranges = [(min([each_row[i] for each_row in rows])
for i in range(len(rows[0]))]
# Step 1 of alg
clusters = [[random_place.random()*(ranges[i][1] - ranges[i][0])+ ranges[i][0]
for i in range(len(rows[0]))] for j in range(k)]
last_matches_list = None
for iteration_num in range(100):
print 'Iteration %d' % iteration_num
best_matches_list = [[] for i in range(k)]
# Step 2
for j in range(len(rows)):
row = rows[j]
best_match = 0
for i in range(k):
calculated_distance = distance_metric(cluster[i], row)
if calculated_distance < distance_metric(clusters[best_match],row): best_match = i
best_matches_list[best_match].append(j)
# If nothing has changed, then algorithm is done
if best_matches_list == last_matches_list: break
last_matches_list = best_matches_list
# Move centroid to average position of its objects
for i in range(k):
average = [0.0]*len(rows[0])
if len(best_matches_list[i]) > 0:
for row_id in best_matches_list[i]:
for m in range(len(rows[rowid])):
average[m] += rows[row_id][m]
for j in range(len(average)):
average[j] /= len(best_matches_list[i])
clusters[i] = average
return best_matches_list
References
The previous content is based on Chapter 3 of the following book:Segaran, Toby. Programming Collective Intelligence: Building Smart Web 2.0 Applications. Sebastopol, CA: O'Reilly Media, 2007.
Next: Clustering Algorithms Index
Back to: Hierarchical Clustering