Project 7: Assocation Rule Mining with Wikipedia Tag Data Set
Project Goal
The goal of project is discovering the internal association rule in thouands of wikipedia tags and exploring association rule algorithms. The article tag is arbitraraly given by the online user. Certain tag attributes are found to be related each other. The association rule algorithm discovers the correlation relationship ammong the tags. The association result is helpful to define well-categorized tag attribute for future, and also can help to improve the accuracy for clustering algorithm when selecting subset of low-correlated tag feature.Wiki10+ Data Set
I used the same data set Wiki10+ as in project 6. However, I extracted much more tag attributes and data object in this project since the primary goal is discovering the correlation among multiple tags.Data Mining Toolkit
The following data mining algorithms and tasks are performed in WEKA3.6. WEKA is open source software. It contains tools for data pre-processing, classification, regression, clustering, association rules, and visualization. WEKA 3.6 is the latest stable version of WEKA. I installed WEKA 3.6 on Windows XP with JDK 1.6.Data Pre-Processing
- Set up Database Schema
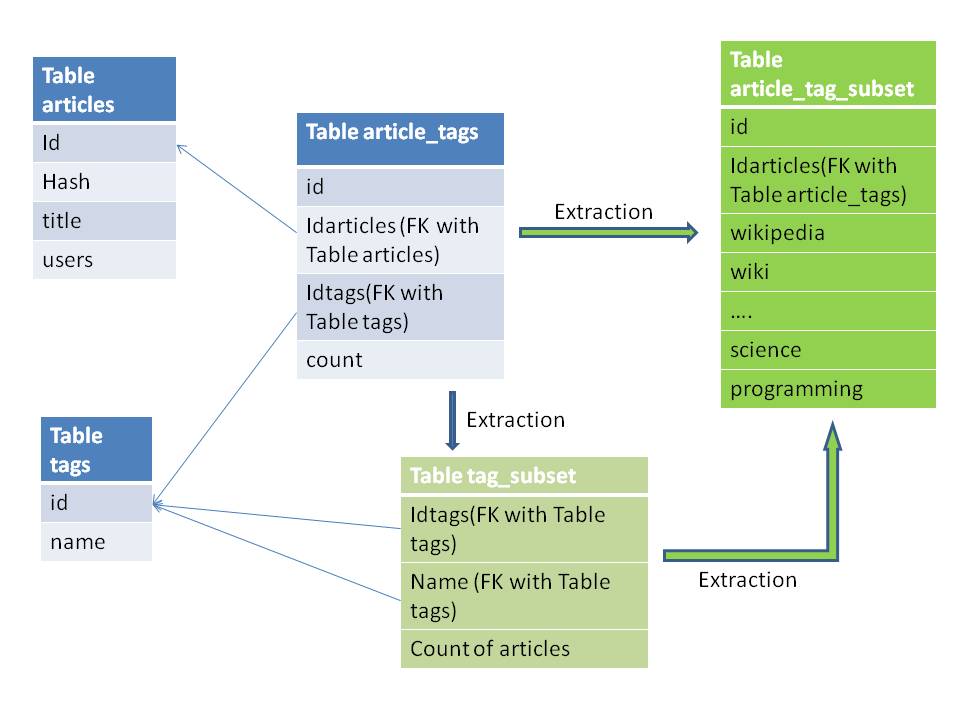
I created two tables tag_subset and article_tag_subset to construct the idea subset for data mining. The overall tag attributes is 20,000+, and can not fully loaded into weka. Also most tag attributes are only used in several articles. Therefore selecting the popular tag attribute as the subset is more effecient for association rule mining process.
The tables in blue color stores the raw data extracted from xml file, and they were created in project 6. Table tag_subset holds the popular tag subset by counting the frequency of tag attributes in articles. Table article_tag_subset holds the subset article data object with the count of selected tag attributes. Below is the overall database schema.
- select subset of article
In order to include as many data objects as possible, all the 2483 articles are loaded in the table article_tag_subset. Below is the statistic data for all articles data set.
total number of tags: 21107 total number of articles: 2483 number of tags in a article: Min: 4 Max: 30 Mean: 21.975 Stddev: 7.245 frequency of tags in all articles: Min: 1 Max: 2005 Mean: 2.585 Stddev: 18.613 - select subset of tags
I chose the top 100 popular tags out of 21107 for association mining. The popularity of the tag is measured by the frequency of the tag occuring in all articles. I sorted the popularity in the database by joining table articles, tags, article_tags. The subset of 100 popular tag is as below. Column name is the name of tag. Column count(idarticles) is the frequency of the tag.
name idtags count(idarticles) wikipedia 217 2005 wiki 225 1045 reference 238 685 history 211 437 research 233 364 science 357 315 programming 745 238 culture 374 236 people 270 227 philosophy 273 217 interesting 561 211 article 219 207 art 420 197 politics 678 183 design 215 182 software 434 172 language 407 167 books 268 165 psychology 320 152 technology 884 152 music 236 150 theory 323 149 math 553 146 development 743 146 computer 404 145 religion 699 138 literature 276 134 education 580 122 information 552 117 business 624 116 health 336 113 mathematics 554 105 writing 271 102 definition 423 102 fun 535 100 internet 617 99 inspiration 723 99 encyclopedia 1309 97 linux 428 97 articles 572 96 cool 1484 95 web 292 93 english 509 93 economics 514 92 travel 1186 91 architecture 889 90 reading 468 89 physics 1153 87 film 632 86 network 2682 82 biography 563 81 video 432 80 learning 577 80 games 397 80 algorithms 2034 78 book 373 78 - 2140 77 security 1109 77 tools 251 76 opensource 444 75 movies 786 74 hardware 252 73 words 1654 71 work 667 70 funny 287 70 social 891 70 management 792 69 free 972 68 usa 239 68 info 395 68 biology 1066 67 game 1770 67 ideas 418 66 school 719 66 tech 817 66 list 489 66 artist 892 65 statistics 518 65 algorithm 1502 63 web2.0 1256 62 photography 814 60 media 886 60 future 2262 60 food 981 60 computers 1735 59 mind 622 58 read 234 57 finance 869 57 society 501 57 humor 237 56 movie 855 56 windows 1623 55 artists 1341 55 computing 294 55 thesis 854 55 ai 1265 54 of 704 54 @wikipedia 591 54 todo 2443 53 brain 1067 53 - Construct Article Tag Subset
The table article_tag_subset then constructs its columns from the selected 100 tag attributes. Each data object has 100 tag attributes. The numeric value of attributes indicates the original count number of the tag. If the article does not have the tag, the value is 0. I developed a python script to extract the data from the related table. The main function is below.
def add_tag_column(self): try: if self.cursor.execute('select name,idtags from popular_tags'): rows=self.cursor.fetchall() for row in rows: try: self.admincursor.execute ('ALTER TABLE article_tag_subset ADD COLUMN `%s` INT(11) NOT NULL DEFAULT 0' % (row[0])); self.admincursor.execute ('update article_tag_subset, article_tags set %s=`count` where article_tag_subset.idarticles=article_tags.idarticles and idtags=%d' % (str(row[0]), int(row[1]))) self.adminconn.commit() except Exception, xx: traceback.print_exc() except Exception,x: traceback.print_exc() return -1Here is an data object from table article_tag_subset. As you will see, only a few attributes are present in the data object, the rest attributes are non-present.
idarticle_tag_subset idarticles wikipedia wiki reference history research science programming culture people philosophy interesting article art politics design software language books psychology technology music theory development math computer religion literature education information business health mathematics writing definition fun inspiration internet linux encyclopedia articles cool web english economics travel architecture reading physics film network biography video games learning algorithms book - security tools opensource movies hardware words work funny social management free usa info biology game ideas school tech list artist statistics algorithm web2.0 photography media future food computers mind read finance society humor movie computing thesis artists windows of @wikipedia ai brain todo 1 15 3 1 0 5 1 0 0 0 0 0 0 2 0 0 4 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Association Rule Mining
- Discretized attribute
The association rule mining algorithm only applies for the nominal data attribute. Then I used remove and discretize filter to preprocess the data. The remove filter will remove the id, title data attributes from the data set. Due to the 1G memory size limitation, WEKA failed to build the association model for the dataset which has more than 10 tag attributes. So the remove filter delete the extra tag data and leaves 10 tags in pre-processing.
Discretize filter transforms the numeric data into nominal data by splitting the value into 10 groups. Here is the configuration parameter for discretize filter and the attribute summary after discretize.


- Aprior Algorithm
I applied Apriori algorithms in wikipedia tag dataset. It is the basic algorithm in association rule mining algorithms. It iteratively reduces the minimum support until it finds the required number of rules with the given minimum confidence. Here is the configuration page I used in aprior algorithm.

WorkFlow in WEKA
The whole workflow I created for mining the association rule in tag data set is as below. In the workflow, It processed 2359 article data with top 10 tag attributes.
Association Rules Result
- Aprior Performance Metric
- Minimum support: 0.95 (2359 instances)
- Minimum metric
: 0.9 - Number of cycles performed: 1
- Generated sets of large itemsets
- Size of set of large itemsets L(1): 10
- Size of set of large itemsets L(2): 45
- Size of set of large itemsets L(3): 120
- Size of set of large itemsets L(4): 210
- Size of set of large itemsets L(5): 252
- Size of set of large itemsets L(6): 209
- Size of set of large itemsets L(7): 115
- Size of set of large itemsets L(8): 37
- Size of set of large itemsets L(9): 5
- Best rules found
- culture='(0-16]' 2476 ==> research='(0-47.8]' 2476 conf:(1)
- reference='(0-73.2]' culture='(0-16]' 2474 ==> research='(0-47.8]' 2474 conf:(1)
- science='(0-33.4]' 2473 ==> research='(0-47.8]' 2473 conf:(1)
- reference='(0-73.2]' science='(0-33.4]' 2471 ==> research='(0-47.8]' 2471 conf:(1)
- programming='(0-71]' culture='(0-16]' 2470 ==> research='(0-47.8]' 2470 conf:(1)
- reference='(0-73.2]' programming='(0-71]' culture='(0-16]' 2469 ==> research='(0-47.8]' 2469 conf:(1)
- science='(0-33.4]' culture='(0-16]' 2468 ==> research='(0-47.8]' 2468 conf:(1)
- science='(0-33.4]' programming='(0-71]' 2467 ==> research='(0-47.8]' 2467 conf:(1)
- reference='(0-73.2]' science='(0-33.4]' programming='(0-71]' 2466 ==> research='(0-47.8]' 2466 conf:(1)
- reference='(0-73.2]' science='(0-33.4]' culture='(0-16]' 2466 ==> research='(0-47.8]' 2466 conf:(1)
- Discretized attribute