Wikipedia Data Mining Project
Project Goal
The goal of project is discovering the internal pattern in wikipedia data set and exploring various date mining algorithms. The cluster algorithm can group the wikipedia articles based on similarity, and forms thousands of data objects into organized tree to help people view the content. Other association and classsification algorithm might be tried as well and see if any other correlation relationship exists in wikipedia data set.Wiki10+ Data Set
Wiki10+ is a dataset created during April 2009 with data retrieved from the social bookmarking site Delicious and Wikipedia by Natural Language Processing and Information Retrieval Group at UNED. It contains 20,764 unique URLs of English Wikipedia articles and their corresponding tags.
The data set file can be downloaded here:<articles> ... <article> <hash>MD5 hash for document's URL</hash> <title>The title of the article</title> <users>Number of users annotating it</users> <tags> ... <tag> <name>Tag name</name> <count># of users who annotated the tag</count> </tag> ... </tags> </article> ... </article>each article has 4 attributes including hash, title, user, tags. The tag attribute has as many children as needed sub-tags. The number of children within tag attribute is from 10 to 100. There are roughly 20,000 records in total. The attribute types are both numeric and nominal. The attribute types are both numeric and nominal.
Data Mining Toolkit
The following data mining algorithms and tasks are performed in WEKA3.6. WEKA is open source software. It contains tools for data pre-processing, classification, regression, clustering, association rules, and visualization. WEKA 3.6 is the latest stable version of WEKA. I installed WEKA 3.6 on Windows XP with JDK 1.6.Data Pre-Processing
To get the xml data set work with WEKA, I first create a python script which extracts the xml contents and stores the data in MySQL database. Beautiful Stone Soup is similar to Beautiful Soup library in Text Book Collective Intelligence. Beautiful Stone Soup is suitable for processing arbitrary XML file. It parses the xml file and constructs the nested attributes in a tree structure for the programmer. The users can get the attributes value based on the key.
The MySQL database schema models the data attributes into three tables. Article table includes all the aticle's attributes. For example, the title and number of users who annotated the articles. The tag table contains all the distinct tag name in the data set. article_tag table records the relationship between article, tag and the number of count which the article was annotated with the tag name. After the xml data was dumpped into MySQL database, I set up a database connection from WEKA to MySQL datbase. WEKA works well with database source and provides many options to statistic and visualization tool for data processing.
Since the data set includes 20,000 articles and 200,000 tags, it is not pratical to load all the data into WEKA for processing. I discovered that most of tag names was only referenced for a few articles. So I sorted the tag name in terms of their popularity among the articles at first and selected top 3 tags for the following processing. Then I chose a subset of data. It contains 200 articles which have one of the top 3 tags at least.
Cluster Algorithms
I applied cluster algorithms in wikipedia dataset and hoped to organize all the article contents in a viewing tree. The similiary among the articles will be explored as well. Cluster algorithms groups the similiar content into different clusters and help people to discover the articles with same topic.K-means Cluster
K-means clustering technique is a basic and simple clustering algorithm. It first choose K initial centroids, where K is specified by user, namely, the number of clusters desired. Each point is then assigned to the closest centroid, and each collection of points assigned to a centroid is a cluster. Then centroid of each cluster is then updated based on the points assigned to the cluster. The process repeats until no pint changes clusters, or until the centroids remain the same.Hierarchical Cluster
Hierarchical clustering technique is another important category of clustering algorithms. It starts with the points as individual clusters, and merge the closest pair of clusters at each step until only one cluster remains.WorkFlow in WEKA
I tried the Hierarchical cluster and SimpleKMean cluster to analyze the tag data. In the workflow, I loaded 200 article data with top 3 tag attributes (wikipedia, wiki, reference) as the sample data set. The distance functions in two cluster component are configured with Euclidean distance. The screen shot of the WEKA workflow I designed to analyze the data as below.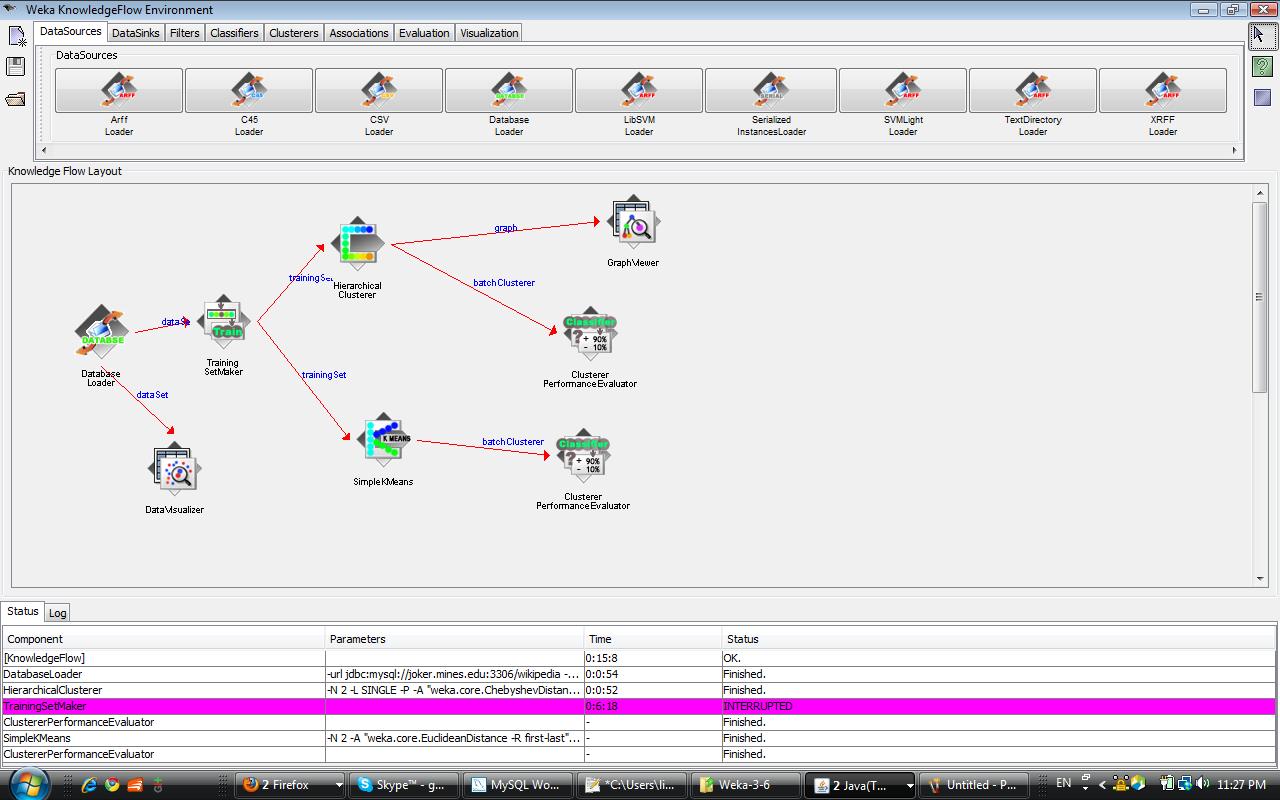
Result
kMeans
Number of iterations: 14
Within cluster sum of squared errors: 1.9115225831375122
Missing values globally replaced with mean/mode
Cluster centroids:
| Cluster# | ||||
|---|---|---|---|---|
| Attribute | Full Data | Cluster 0 | Cluster 1 | Cluster 2 |
| (200) | (2) | (26) | (172) | |
| wikipedia_count | 4.725 | 64 | 11.8077 | 2.9651 |
| wiki_count | 1.265 | 17.5 | 5.3462 | 0.4593 |
| reference_count | 0.77 | 19.5 | 1.8077 | 0.3953 |
| Clustered Instances | |
|---|---|
| 0 | 2(1%) |
| 1 | 26(13%) |
| 2 | 172(86%) |